


Microsoft accelerates its lead in the AI race with the launch of Phi-4-mini-flash-reasoning model. Introduced on July 9, 2025, this small language model (SLM) boasts state-of-the-art architecture, redefining speed for reasoning models.
Designed for diverse environments, including mobile applications, edge devices, and resource-constrained platforms, the new edition of the Phi model family can address critical tasks. The model is designed to offer high efficiency and reduced latency, enabling faster results with improved reasoning performance.
Let’s explore the capabilities and advantages of Microsoft’s new AI model…
What sets Phi-4-Mini-Flash-Reasoning Model Apart?
Phi-4-mini-flash-reasoning is not just another edition of Microsoft’s Phi family but a notable advancement within the lightweight open model space, with 10 times faster performance than its predecessors. Suitable for on-device and on-premises applications, this model can potentially advance educational and real-time logic-based platforms.
Built on a new hybrid architecture, this AI model is capable of achieving 10 times higher throughput alongside advanced reasoning capabilities. This open model has a 64K token context length and is trained on high-quality synthetic data. All these attributes contribute to the reliable deployment of high-performance computing abilities.
Phi-4-Mini-Flash-Reasoning Model’s Architectural Significance:
Phi-4-mini-flash-reasoning model is empowered with SambaY, a decoder-hybrid-decoder architecture. The architecture employs a simplified yet effective approach to sharing representations between layers, utilizing the Gated Memory Unit (GMU). Additionally, SambaY architecture possesses a self-decoder that combines Sliding Window Attention (SWA) with the State Space Model, Mamba.
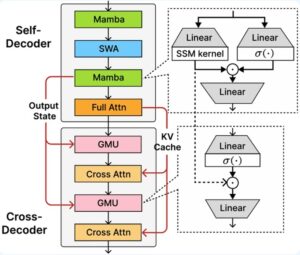
Source: Microsoft Azure
These features support the new model of Microsoft, providing out-of-the-box performance that addresses a multifaceted set of complex tasks. It is now available on Azure AI Foundry, Hugging Face, and NVIDIA API Catalog.
What Advantages Does SambaY Architecture Offer?
Since SambaY integrates Gated Memory Unit (GMU), it assists Microsoft’s new model to achieve enhanced decoding efficiency, elevating contextual fidelity in long-form tasks. The key benefits of such architecture involve-
- Elevated decoding efficiency.
- Sustains linear pre-filing time complexity.
- Enhanced Scalability.
- Advanced long context performance.
- 10 times more throughput with low latency.
Benchmarks Achieved:
Phi-4-mini-flash-reasoning model reflects advanced capabilities, outperforming previous models of the Phi family and other small language models.
In the remarkable math benchmarks for long sentence generation, AIME24, the latest model achieved a score of 52.29, whereas its previous model could reach 48.13. Similarly, in MATH-500, Phi-4-mini-flash-reasoning attained 92.45, while its predecessor achieved 91.2.
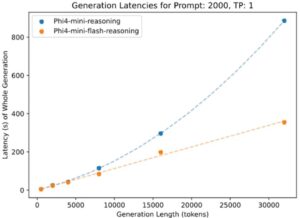
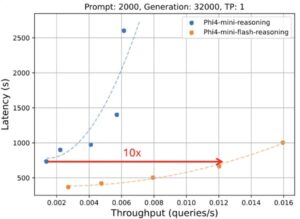
Source: Microsoft Azure
In Microsoft’s Generation Latencies for Prompt: 2000 test, the new model reflected remarkable throughput with lower latency. Notably, in the test for Prompt: 2000 and Generation: 32000 tests, the model could achieve 10x more throughput with significantly lower latency.
Where can Microsoft’s New AI Model be used?
Since the new small language model of Microsoft exhibits advanced math reasoning capabilities with considerable latency and enhanced throughput, it can be implemented for various purposes. Here are some use cases:
- Learning Platforms: The SLM provides real-time feedback with enhanced throughput, making it an ideal solution for learning platforms, such as generative chatbots.
- On-device Assistants: The model is capable of efficient and scalable reasoning, which is adaptable for both on-premises and on-device models. Hence, it can also be helpful while integrating with edge-based logic assistants for devices like mobile phones.
- Tutoring Apps: Due to enhanced reasoning abilities, this model is also compatible with learning or tutoring apps that aid in advancing learners’ performance.
Privacy Parameters of Microsoft:
Microsoft has been a leader in developing and utilizing trustworthy AI, enabling businesses to harness the potential of AI securely and safely. Similarly, the Phi family of models also adheres to Microsoft’s ethical AI propositions, including transparency, accountability, fairness, safety and reliability, inclusiveness, alongside privacy and security.
The Phi-4-mini-flash-reasoning model, in this regard, implements a resilient post-training methodology that assists in ensuring helpfulness, mitigating harmful outcomes, and prioritizing various safety standards. The methodology includes Supervised Fine-Tuning (SFT), Reinforcement Learning from Human Feedback (RLHF), and Direct Preference Optimization (DPO).
Microsoft combines these elements alongside a commitment to prioritizing security, safety, and privacy while developing and implementing trustworthy AI.
Looking Ahead!
Phi-4-mini-flash-reasoning model is ideal for a wide range of on-device and on-premises tasks since it can function on a single GPU. The safety features and adherence to Microsoft’s commitment to develop trustworthy AI are what set this model apart from other small language models. However, the most interesting and core element is its unique architecture, which allows the model to operate efficiently with limited latency.
The launch of this simple yet faster model is potentially Microsoft’s approach to making SLMs more capable and accessible. Notably, its integration with local devices can pose difficulties initially; however, its deployment within smart systems can drive significant results.
Are you curious about the latest technologies transforming various industries? Follow HiTechNectar to stay one step ahead with valuable tech insights.
F&Qs:
Q1. What is the difference between Phi 3.5 and Phi 4 mini?
Answer: The basic difference between Phi 3.5 and Phi 4 mini is their focus. While Phi 3.5 is focused on advanced multilingual support and improved performance, Phi 4 mini focuses on increased natural language instruction prompting and sophisticated reasoning.
Q2. What are the memory requirements for Phi 4?
Answer: The minimum RAM requirement of Phi 4 is 32GB DDR4; however, the recommended RAM setup is 64GB DDR4. Best performance requires 128GB DDR5 or DDR4 memory support.
Q3. How to train phi4?
Answer: Training Phi 4 model involves several stages, such as loading the model and tokenizer, preparing and processing the dataset, enabling model inference, setting up the model with LoRA (Low-Rank Adaptation), and initiating model training.
Q4. What is the context size of Phi 4 mini?
Answer: Phi 4 mini is a lightweight open model with a context size of 128K tokens.
Recommended Reads:
Microsoft Notepad App for Windows 10
Walmart tie-up with Microsoft on cloud technology
Microsoft Goes Down: Indeed, The Biggest Outage in History!