


As applications grow, so does the need to handle massive amounts of data smoothly and efficiently. Imagine a social media platform with millions of users worldwide – how does it ensure fast, reliable performance without buckling under pressure? Database design strategies like sharding and partitioning make this possible.
This blog discusses sharding and partitioning in detail. Let’s begin.
What is Sharding?
Database design techniques like sharding are mostly used for horizontal partitioning over several computers or databases. Together, the shards form a single logical database, yet each one operates as a distinct database. Sharding aims to improve speed by reducing the strain on each database by allocating data based on a specified key, like a customer ID or geographic area.
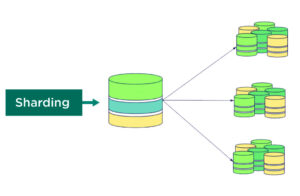
An example of sharding can be seen in a social media platform that divides user data by user ID range. Users with IDs 1–1,000,000 might be stored on one shard, while users with IDs 1,000,001–2,000,000 are stored on another. This allows the platform to efficiently distribute user requests across multiple servers, improving performance and enabling the system to scale as the user base grows.
What is Partitioning?
Partitioning, which is often used to refer to vertical partitioning, is the act of splitting a database into discrete areas, or partitions, that may be stored and handled independently. There is no need for distribution across several servers because this division takes place within a single database system. By dividing data into smaller, easier-to-manage chunks, partitioning is frequently used to improve the availability, performance, and management of big databases. This kind of approach may greatly improve query performance and simplify processes.
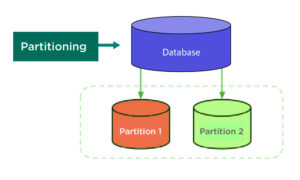
An online retailer partitions its orders database by year, storing each year’s orders in a separate partition. This setup makes it easier to archive old data and improves query performance for recent transactions.
Key differences in Sharding and Partitioning
Following table illustrates the key differences between sharding and partitioning –
| Sr.No. | Key Points | Sharding | Partitioning |
| 1. | Scale | Primarily used for horizontal scaling across multiple machines. | Used for data management and optimization within a single database server. |
| 2. | Data Distribution | Each shard holds a unique subset of data; no overlap between shards. | Partitions can be within one database instance and may overlap logically. |
| 3. | Maintenance Complexity | Requires managing multiple servers, making it complex to maintain. | Simpler to maintain, as partitions are usually within a single server. |
| 4. | Performance Impact | Reduces load by distributing data, improving performance across servers. | Optimizes query performance within a single server. |
| 5. | Use Cases | Ideal for large datasets needing high scalability (e.g., global platforms). | Suitable for performance optimization in local or single-server databases. |
| 6. | Failure Isolation | Failure in one shard is isolated, minimizing impact on other shards. | Failures in one partition may affect the entire database server. |
| 7. | Data Model Adjustments | Requires adjusting the data model for shard keys and data distribution. | Requires designing partitioning keys but within a simpler, single-instance setup. |
Advantages of Sharding
By dividing the database load among several servers, sharding enhances application performance, especially for read-intensive applications. By distributing load and data evenly, it reduces bottlenecks. Sharded architectures increase fault tolerance and reliability since the failure of one shard doesn’t affect the others. By assigning distinct shards to each tenant, sharding also improves security and speed by offering data separation for apps that serve many tenants.
Disadvantages of Sharding
Because maintaining several databases necessitates sophisticated orchestration and monitoring techniques, sharding adds operational complexity. Additionally, it poses data distribution hurdles that might result in unbalanced loads and performance problems. Applications may require more time and money to create when they are adapted to a sharded architecture. In transactional systems, it is difficult to maintain consistency between shards.
Advantages of Partitioning
Database partitioning enhances query performance by enabling efficient data access, reducing processing time, and improving system responsiveness. It simplifies maintenance procedures like data purges, backups, and schema modifications, allowing them to be completed quickly without compromising the database’s availability. Additionally, because of this segmentation, maintenance may be limited to partitions without impacting the database. For workloads like massive volumes of historical data, partitioning improves performance by executing queries more quickly.
Disadvantages of Partitioning
Although partitioning might make data administration easier, it can also make things more complicated. Prior preparation and knowledge of data access patterns are necessary. Performance can be adversely affected by data skew caused by improper partitioning techniques. Performance penalties can also arise from queries that are not properly aligned with the partitioning key, particularly those that access numerous partitions or do not use the partition key in their predicates.
Final Words!
Sharding and partitioning both offer smart solutions for managing and scaling databases, but each has unique advantages. Sharding works best for systems needing to scale across multiple servers, bringing resilience and performance to applications with large, active user bases. Partitioning shines within a single server, offering quicker queries and more straightforward maintenance for structured data.
We hope this blog content will help our readers to understand sharding and partitioning. For more tech-savvy content, keep visiting our blogs at HitechNectar.
You May Also Like to Read:
Database Management System Software Perform Operations Like Creating, Storing or Deleting Data