


Deep Learning Architectures for Computer Vision offer multi-layer components to execute tasks. Moreover, it enables neural networks to prioritize any image’s pivotal features and aspects. Further, Deep Learning architectures are the ideal solutions for Computer Vision as it helps resolve complex problems.
According to Jason Brownlee in the book, ‘Deep Learning for Computer Vision’, “Deep learning methods can achieve state-of-the-art results on challenging computer vision problems such as image classification, object detection, and face recognition.”
Further, Wayne Thompson, SAS Data Scientist, states, “Computer vision is one of the most remarkable things to come out of the deep learning and artificial intelligence world. The advancements that deep learning has contributed to the computer vision field have really set this field apart.”
Hence, in this article, we will walk understand the various Deep Learning Architectures for Computer Vision.
Know about the Deep Learning Architectures for Computer Vision
What is Computer Vision?
Jason Brownlee in his article, A Gentle Introduction to Computer Vision, states “Computer Vision, often abbreviated as CV, is defined as a field of study that seeks to develop techniques to help computers “see” and understand the content of digital images such as photographs and videos.”
In other words, CV is a branch of Artificial Intelligence that enables computers to comprehend visual assets. Further, digital images and videos use deep learning models to build machine accuracy to classify objects. It also develops the ability of the computer to “see” and react to the visuals.
According to Programming Computer Vision with Python, 2012, “Computer vision is the automated extraction of information from images. Information can mean anything from 3D models, camera position, object detection and recognition to grouping and searching image content.”
Computer Vision offers its functions to enhance customer experience, reduce costs, and improve security for data. Further, it generates artificial models to imitate and replicate tasks to recognize and classify visual assets.
How does Computer Vision work?
Here are the three basic steps in Computer Vision:
- Procuring an Image: Firstly, it is pivotal for the system to procure an image of large sets of images from various sources. Moreover, these images need to be collected and processed in real-time using videos, photos, 3D solutions, etc.
- Analyzing the Image: Further, pre-trained Deep Learning models automate image analysis for Computer Vision.
- Comprehending Images: Above all, comes the final step which is comprehending and interpreting images to identify, detect, and classify an object.
Types of Computer Vision Tasks:
Here are the various tasks executed by Computer Vision:
- Firstly, Image Segmentation is the segregation of the objects within an image into several regions or features for analysis.
- Moreover, Object Identification refers to detecting a peculiar object in the image. Further, Advanced Object Identification detects multiple objects within an image for analysis.
- Facial Recognition is also a CV task that uses advancements in object identification to identify human faces in an image.
- Further, Edge Perception is the process of detecting the outside edge of an object or a landscape for a better perception of the image. Moreover, Feature matching comes under this task as it creates patterns for features and similarities in an image.
- As the name suggests, Pattern Discovery is the process of identifying patterns within the image. Moreover, it detects the repetition of shapes, colors, and other visual symbols in the image.
- Moreover, Image Classification classifies images into various categories and groups.
Applications of Deep Learning Architectures in Computer Vision
As the requirements for Computer Vision increase, it is replacing statistical techniques with Deep Learning architectures and neural network models. Although there are various challenges in Computer Vision that need addressing. Therefore, deep learning architectures enable Computer Vision to achieve results for complex problems.
-
Image Classification:
Image Classification refers to labeling the complete image or the photo. It is also referred to as object classification and more commonly as image recognition. Therefore, Deep Learning Architectures enable Computer Vision to execute tasks to classify and categorize large sets of images. For instance, labeling x-rays as detecting diseases or not is binary classification. Similarly, classifying handwritten content is a multiclass classification.
-
Object Detection:
Object Detection is the classification of images using localization. Further, an image may contain multiple objects that require localization and classification. Although it is a more challenging task in comparison to Image classification. Hence, Deep Learning Architectures simplifies the process of image analysis and analyzes multiple objects in the image.
-
Object Segmentation:
Object segmentation aka Semantic Segmentation detects objects using a line around various objects in the image. Although image segmentation is a more generic challenge segmenting images. Further, Deep Learning Architectures train models to identify objects and assign segments. Moreover, it segments objects using particular pixels in the image.
Understanding CNNs: Deep Learning Techniques and Developments
CNNs or Convolutional Neural Networks are a key component of Deep Learning Models in Computer Vision. Moreover, the concept was invented by Yann Lecun in the 1980s. CNNs are neural networks that efficiently recognize and capture patterns and objects in multidimensional images. Further, CNNs include three major neural layers, that are:
- Convolutional Layers: It refers to the process of convoluting images using multiple kernels in the CNN. Further, the advantage of convolution it enables faster learning training models.
- Pooling Layers: This layer is responsible for charging the reductions in spacial dimensions and measurements within the input volume of a convolutional layer. Although it does not impact the depth dimensions in the volume. Moreover, it executes subsampling or downsampling to avoid loss of information by reducing size leads.
- Fully Connect Layers: High-end reasoning in neural networks comes above all multiple convolutional layers and pooling layers to perform neural network tasks using fully connected layers. Moreover, it fully connects neurons to activate functions in the previous neurons.
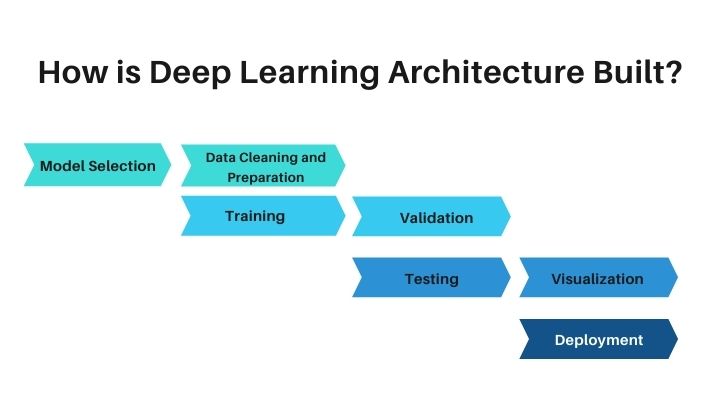
Here are the Top Deep Learning Architectures for Computer Vision
-
AlexNet (2012)
AlexNet is a Deep Learning architecture for Computer Vision based on LeNet architecture. It incorporates five convolutional layers and three fully connected layers as well as dual pipeline structures. It also accommodates the functions of two GPUs while training models. Further, it uses rectified linear units (ReLU) instead of sigmoid or Tanh activation functions. ReLU also enables AlexNet to train models with simpler and faster computations.
-
GoogleNet (2014)
GoogleNet or Inception V1 is also based on the LeNet architecture. It includes twenty-two layers of smaller groups of convolutions known as inception modules. GoogleNet uses the inception modules to resolve large network problems and RMSprop to decrease the computational cost. Moreover, RMSprop integrates algorithms that enable adaptive learning to rate techniques.
-
VGGNet (2014)
VGGNet or VGG 16 is 16 layer architecture that may also include 19 layers in some models. It generally includes convolutional layers and a few pooling layers. Further, VGG originates from the notion of deeper networks that include smaller filters.
Conclusion:
In conclusion, Deep Learning Architectures for Computer Vision offer advancements in the interpretation of images, videos, ad other visual assets. It also uses multiple nodes and neurons to train algorithms to offer greater capabilities for decision-making processes.
You May Also Like to Read:
Here are the Proven Real-world Artificial Neural Network Applications!
Know How Transformers play a pivotal part in Computer Vision