


Everyone knows the importance of schema when it comes to databases. The aim of designing any database schema is to reduce access times with efficient searching.
Normalization and denormalization are two processes used to improve the performance of relational databases.
Relational databases comprise of data arranged in tables in the form of rows and columns. The normalization process is used to segregate these data into different tables.
The central idea here is to arrange the data so that data specific to one object is placed in one table.
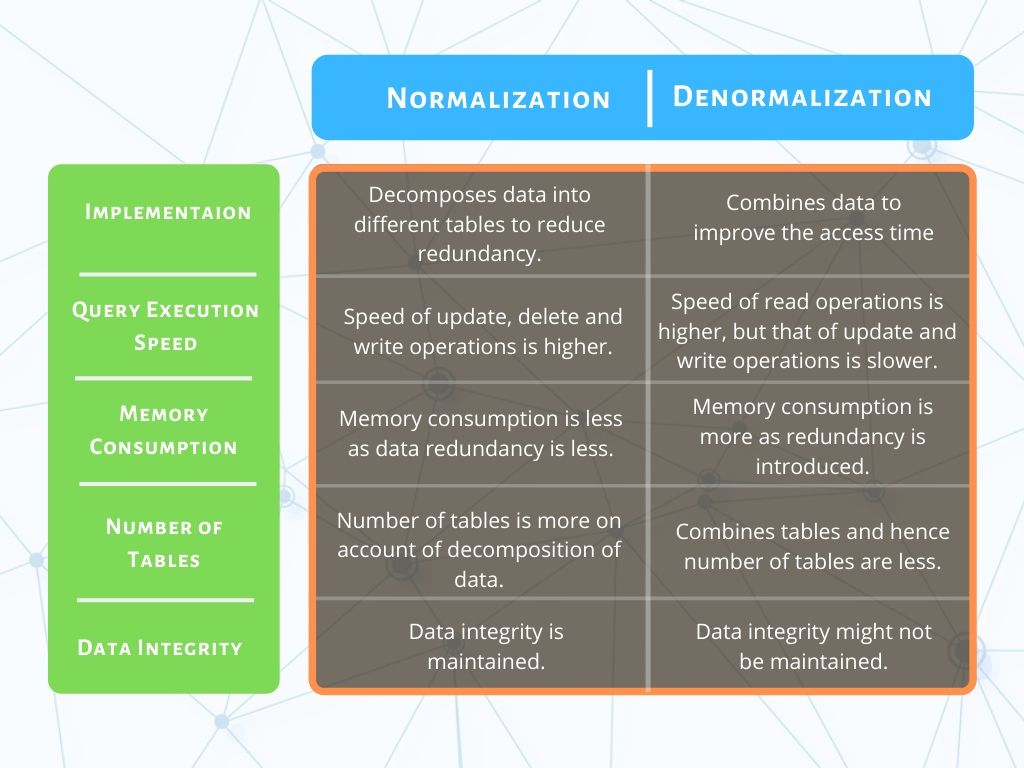
Normalization decomposes data into different tables to reduce redundancy. This helps reduce the anomalies introduced during processes such as insertion, deletion, and updating.
Redundancy in data could lead to inconsistency between different versions of the data stored at different places.
Normalization helps reduce this problem by adhering to the principles of data integrity.
A fully normalized database allows easy extension of the database structure without changing the existing database. It is possible to add new columns and datatypes to the current database.
De-normalization is implemented on a normalized database. The primary aim is to reduce the time required to execute any query on the database.
For this purpose, denormalization combines different data sets to improve time efficiency. This process introduces redundancy in the database.
De-normalization combines different tables. Thus, the total number of tables in the database decreases.
Constraints are used in the process of denormalization to ensure that the various copies of data are synchronized, and data integrity is maintained.
Also Read: OLTP vs OLAP: Understanding the Differences
The name would suggest to some, but denormalization is not the same as data that is not normalized.
Both techniques improve the overall performance of the database, but they are quite different. Here are some of the differences between the two:
Normalization is implemented on raw data. It is the process of decomposing the existing the data into different tables to reduce redundancy and inconsistency.
De-normalization is implemented on normalized data. It is the process of combining data to improve the access time.
It leads to increased redundancy of data.
Normalization uses a column called the “key” to establish a relation between the different related tables. The use of key often leads to increased read time during various joins.
To maintain data integrity, denormalization uses constraints and triggers on the database.
Although the read time is significantly reduced, de-normalized data requires more time to execute write, and update queries.
This is because multiple copies of the data need to be updated or written during one query.
Normalization focuses on efficient usage of memory by eliminating duplicate copies of the same data.
De-normalization requires more data as it stores multiple copies of related tables in the database.
De-normalization is heavier on data usage as compared to normalization.
As normalization segregates the data into various tables for different entities, the number of tables increase with each entity added.
De-normalization combines the different tables of related entities in a normalized database.
Thus, the number of tables in the normalized database is more than in the de-normalized database.
One of the aims of normalization is to maintain data integrity.
However, in denormalization, data integrity is not necessarily maintained.
As mentioned earlier, denormalization uses constraints and triggers to maintain data integrity. However, this increases the complexity and cost of maintaining the data.
Normalization is used in places where there is regular insertion, updating, or deletion of data, such as OLTP systems.
De-normalized data is preferred in places where the joins are expensive, and the data needs to be frequently read from.
Conclusion
Normalization and denormalization, both have their pros as well as cons. Each focuses on different outcomes and hence have different processes.
Whether or not to opt for denormalization after normalization of data, is up to the requirement of the system being developed.
You May Also Like to Read: CMDB vs. Asset Management: Difference Explained