


Imagine you are trying to explain something complicated to a very smart friend who takes everything exactly as you say it. You wouldn’t just say one word and expect them to understand. You would give more details, maybe use hand movements, or even show a picture to help them get the full idea. That is exactly what we are learning to do with today’s advanced AI. It is called multimodal prompt engineering, and it means using different types of input, like words, images, and even gestures, to help AI understand things better, just like we do when talking to people.
For years, conversations with an AI were just a matter of typing words into a box and receiving words back. But the world is not words. We look, we listen, we observe. The new AI models, called Multimodal Large Language Models (or MLLMs), are starting to realize this. They can work on input from various “modes”, such as text, images, and soon sound and video, simultaneously. Multimodal prompt engineering model is the art of writing instructions that interleave these modes to lead the AI to the best, most creative, most useful response. It’s not coding; it’s effective communication.
What is Prompt Engineering?
Prompt engineering is the art of asking questions or providing instructions to AI in an intelligent manner in order for it to provide you with the best possible answer.
Imagine you are explaining something in a friendly manner; you have to be specific about what you want. If you just write “explain,” the AI may not necessarily understand exactly what you want. But if you write, “Explain photosynthesis in simple terms for a 10-year-old,” the AI gets a better idea and provides a more helpful response.
It is not about fancy words. It is about understanding how to instruct the AI by providing the correct type of input, whether it be a question, a task, or even combined text and images.
What Is Multimodal Prompt Engineering?
Multimodal prompt engineering is the art of asking smart questions using different types of input, like combining text, images, or even voice, so that the AI understands better and gives you richer, more useful answers.
For example, if you need help in designing a blog post, you could say to the AI, “Here’s a photo of a cloud data center. Can you write a short paragraph explaining what is happening in this image?” Or “I recorded a voice note describing a tech concept. Can you turn it into a clear article?”
That is multimodal prompt engineering that uses images, audio, or video along with text to guide the AI.
Why Does This Even Matter?
You may ask why we must master this new way of communicating. The reason is simple: it closes the gap between human thinking and machine comprehension. We process in a multimodal manner. If you glance at an image of a mountain sunset, your brain doesn’t merely visualize colors and forms; it may remember the sensation of crisp mountain air, the sound of silence, or a particular memory. Regular AI would be able to handle only the text “mountain sunset.” A multimodal model, given the right prompt, is able to start getting closer to that richer, human-level understanding.
This matters tremendously for practically every field. A physician might upload a chest X-ray image and ask the AI: “Interpret this chest X-ray and report any abnormalities in plain language to a patient, comparing it with a normal one.” An architect might upload a facade sketch of a building and ask, “Create three photorealistic rendering styles for this building: modern, classical, rustic.” The model matches the visual information against its extensive knowledge base, all in response to a text prompt.
As per the report, generative AI is likely to contribute the equivalent of $2.6 trillion to $4.4 trillion annually to the world economy across different use cases, much of which will be fueled by such sophisticated multimodal applications. This is not merely a technical improvement; this is a profound change in the way we will work, produce, and address challenges.
How Multimodal Prompt Engineering Actually Works
Let’s walk through the process without the techno-babble. Consider the AI model to be an incredibly smart, hyper-attentive assistant. Your task is to be a good boss and provide clear, concise directions.
A multimodal model prompt engineering is not a question. It’s a bundle that can include:
- Your Text Instruction: The essential question or task.
- An Image (or several images): The picture context for your task.
- The Tone and Style: What you would like the AI to be like in its response.
Magic occurs when the model “blends” these ingredients. It does not merely view the image and read the words independently. It links them, employing the words to know exactly what certain information you want extracted from the image.
Here’s a straightforward example of a traditional AI task and a multimodal prompt engineering AI task.
Weak Prompt: (You upload a picture of a street market that’s bustling.) “Tell me about this.”
Strong, Engineered Prompt: (Same photograph uploaded) “Recognize the varieties of fresh produce that can be seen in the front of this photo. Put them on a table and recommend a recipe that might employ at least three of them.”
The initial prompt is unclear. The AI could talk about the weather or the audience. The second prompt is precise, offers spatial information (“foreground”), requests structured data (“in a table”), and requires a creative endeavor (“suggest a recipe”). This specificity directs the AI to concentrate its immense abilities precisely where you require them.
Let’s understand it with the table:
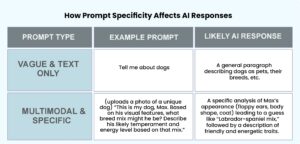
Becoming a Better Conversationalist with AI
The secret to good multimodal prompt engineering is to be precise and situational. Don’t leave it guessing. Indicate to it what you are getting at and tell it what you require. Define the output you would like the response in: a bulleted list, a poem, a JSON object, or a descriptive paragraph. The more context you use, the less ambiguity there is for mistakes.
This space is changing at lightning speed. What you can do today may be improved upon tomorrow. But the principle at the heart will not change: good communication leads to greater outcomes. It’s learning the language of these models to collaborate with them. When we learn how to talk to AI using different types of input, like words, pictures, or even sounds, we are not just using technology anymore. We become part of the process. It is like working together with AI instead of just watching it work. This opens exciting new possibilities that we are only beginning to imagine.
To learn more, visit HiTechNectar!
FAQs
Q1. What are multimodal prompts?
Answer: Multimodal prompts are how we speak to AI in a language beyond words. You can use images, sounds, or even video with words to make it understood more easily, just like we do when we are explaining something to a friend using gestures or pictures.
Q2. What are the three types of prompt engineering?
Answer: There are three primary means of directing AI with prompts:
- Text prompts: With written words or questions.
- Visual prompts: With images or videos.
- Mixed prompts (multimodal): Blending text and images or other input to provide additional context and clarify things.
Q3. What is meta prompt engineering?
Answer: Meta prompt engineering refers to designing prompts that instruct the AI to know how to respond to other prompts. It’s as if one is instructing the AI to think or obey particular rules while answering questions.
Recommended For You:
5 Powerful Frameworks to Write ChatGPT Prompts That Actually Work