


As is rightly said, the right track can lead to the right path. For example, a good teacher can impact your career and drive good outcomes. Can we compare this to machine learning and AI algorithms? Why not.
Machine learning and AI are the tech terms that have been gaining the spotlight in today’s digital world. According to a recent study, the machine-learning market is expected to grow at a rate of 36.08% between 2024 and 2030.
Moreover, to learn effectively you need high-quality training data. This is where data annotation comes into light. To help you understand more, we’ve curated a blog that explains what data annotation is, its types, challenges, and more.
So, without any further ado, let’s get started!
What is Data Annotation?
Data Annotation in simple terms is the method of tagging or labeling raw data to make it easily understandable to machines. Here labeling is into unstructured data such as videos, images, text, etc. This allows machine learning algorithms to identify patterns in data and make accurate predictions.
For instance, if we wish to have an algorithm that recognizes road signs for an autonomous vehicle, we will have a huge and varied dataset of images with labeled road signs of various kinds, angles, weather conditions, lights, and even obstructions such as trees or graffiti. Without road signs (negative examples) is also required to train and ensure accuracy. It’s nothing but making the data clean to drive desirable predictions.
Types of Data Annotation
On the basis of data form, there are different types of data annotation, as mentioned below:
Text Annotation
As the name suggests, text annotation is all about training machines to know more about textual data. For example, a chatbot can be trained to give specific answers to particular questions. Moreover, if the data, here the annotated text is inaccurate, then the chatbot would provide irrelevant results. Thus, you need the right text annotation for a seamless user experience.
Audio Annotation
Audio annotation is all about finding and labeling characteristics in audio data. This includes speaker demographics, mood, emotion, and behavior. Here annotators are required to listen to audio and recognize its different patterns. Plus, audio annotators carry out their tasks through different methods, one of which is timestamps to identify primary events or even changes in audio. They will also recognize and tag individual components such as speech, quiet, background noise, or musical content.
Video Annotation
Video annotation is simply adding tags, metadata, or labels to video content, making it ideal for tasks such as machine learning training models, and analysis. It identifies and marks the elements in the video such as objects, actions, or events to allow machines to understand and deliver the required visual information. Although video annotation is comparable to image annotation, it has a special problem because objects move!
Image Annotation
Image annotation is the act of appending metadata or other information that contributes to identifying and understanding the visual content of digital images. It is an essential step in the training of computer vision models to enable machines to identify objects, individuals, or scenes in pictures.
The operation may involve marking, drawing a bounding box, segmenting a region, or tagging attributes to improve image classification and detection precision. Image annotation also comes into the picture for critical uses such as autonomous vehicles, facial recognition, medical imaging, and content moderation.
Data Annotation Challenges
Here are a few challenges that come with data annotation:
Scalability: Annotating large data requires the proper tools and processes, which can be expensive and time-consuming.
Skill: Domain-specific expertise is required for accurate annotation mainly in domains like healthcare or more.
Quality of Annotation: It’s quite a big task to maintain the accuracy and consistency between annotations, particularly when working with ambiguous or subjective data.
How Can You Get Started with Data Annotation
Check out the steps below to get started:
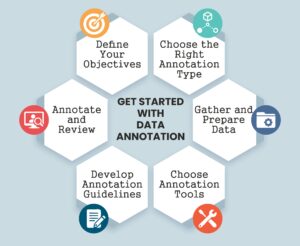
- Define Your Objectives: Firstly, identify the problem you are facing to address and what type of data you need.
- Choose the Right Annotation Type: Pick an appropriate annotation technique on the basis of your data, image, text, video, audio, etc.
- Gather and Prepare Data: Collect raw data from trusted sources and preprocess it to remove irrelevant content.
- Choose Annotation Tools: Make use of data annotation tools such as Labelbox, SuperAnnotate, CVAT) that align with your particular use case and workflow requirements.
- Develop Annotation Guidelines: Curate detailed guidelines to maintain consistency and accuracy throughout the dataset.
- Annotate and Review: Start annotating small batches of data, review samples at regular intervals, and iterate based on feedback to ensure quality.
Wrapping it Up
We’re done! Thanks for reading. Hope you now have a clear understanding of what data annotation is, its types, and how you can kickstart your annotation journey. Annotated data plays a vital role in AI and ML projects. Audio, video, text, or image data can be used to train AI and machine learning systems and get the desired outcomes.
To know more about tech blogs, stay tuned with us.
You May Like:
Why You Need A Data Exfiltration Prevention Tools?
Application Integration and Data Security: Ensuring Safe and Compliant Data Handling