


In the world of Artificial Intelligence, we are constantly looking for ways to make our digital helpers smarter, more accurate, and more reliable. You have seen chatbots and assistants that can write surprisingly well, but sometimes they get things wrong, making up facts or giving out-of-date information. This issue is often called “hallucination.”
To make that work, developers employ a really ingenious trick called Retrieval Augmented Generation, or RAG. It is not just a fancy name; it is actually an entire process, a pipeline, that dramatically enhances how AI models do question-answering. The RAG pipelines form the engine of many of today’s most accurate AI tools, allowing them to reach into and apply very specific, up-to-date knowledge that wasn’t in their original training.
Think of a model without RAG as the student who can use only their early school knowledge. Then think of the student who has already learned how to quickly open a textbook, look up the exact facts needed, and then write a fluent, correct answer; that would be a system with RAG pipelines.
What is a RAG Pipeline? A Simple Overview
RAG pipelines mainly bridge the gap between a powerful language model, which would write out the answer, and an external source of information, generally called the knowledge base. The AI grounds its answers on real, verifiable facts.
The whole process is divided into two major phases: Indexing is the preparation phase, and Retrieval & Generation is generally called the answering phase.
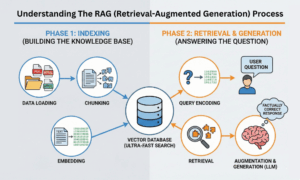
Phase 1: Indexing (Building the Knowledge Base)
Before the AI can answer a question, you have to organize the knowledge you want it to use. You do this in a few key steps:
- Data Loading: You first gather all your documents. This could be company handbooks, customer service logs, PDFs of research papers, or articles from a private website.
- Chunking: It refers to breaking down large documents that are too big for the AI to handle all at once into smaller, manageable pieces, which are also called “chunks.” It’s kind of like breaking a large book into individual paragraphs or short sections.
- Embedding: This is the most important step. An embedding model converts each chunk of text into a special type of numerical code, called a vector. It is not just any random vector; it captures the meaning of the text. Chunks of text with similar meanings will have vectors that are numerically close to each other.
The vectors are then stored in a special place called the Vector Database, which, for this purpose, is designed to support ultra-fast searches based on meaning rather than just keywords.
Phase 2: Retrieval and Generation (Answering the Question)
When a user asks a question, the RAG pipelines spring into action:
- Query Encoding: The question of the user is also converted into a vector, just like the documents were in Phase 1.
- Retrieval: This query vector is searched against the whole Vector Database. It quickly retrieves the top few chunks of documents whose vector is closest to that of the question. These chunks will represent the most relevant pieces of information that might contain the answer.
- Augmentation & Generation (The Answer): These most relevant chunks are then packaged up and sent, along with the user’s original question, to the LLM. It is this retrieved content-this context-that the LLM uses to formulate a fluent, well-written, factually correct response.
The critical step here is that the LLM is no longer guessing or trying to retrieve an answer from its memory but is, instead, reading the facts presented to it before answering. That is why RAG pipelines work so well.
Examples of RAG Pipelines in Action
RAG pipelines are not a theory; they are being used at this very moment to solve real-world problems.
- Customer Support Chatbots: A telecommunications company has implemented a RAG system based on the most recent product manuals, warranty documents, and troubleshooting guides. When a customer queries, “How do I reset the Wi-Fi on my new model X router?” the chatbot pulls out the exact section from the updated manual and creates an accurate, step-by-step response instantaneously and perfectly.
- Legal/Finance Research: A law firm builds RAG pipelines over its internal database of case studies and regulations. The attorney can ask a complex question about a niche law, and the system retrieves and summarizes the specific relevant legal precedents, a greatly informed starting point for them.
- Internal Knowledge Base: A large company has thousands of documents across different departments. An employee asks, “What is the policy for working from home during severe weather?” The RAG system searches the HR, IT, and Operations manuals and gives a single, coherent, and up-to-date answer.
Key Benefits of RAG Pipelines
There are several big advantages of using RAG pipelines compared to using a standard AI model alone:
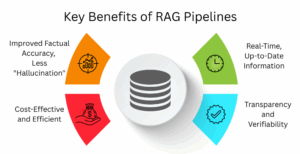
- Improved Factual Accuracy, Less “Hallucination”: By anchoring responses on retrieved, verifiable data, RAG systems significantly reduce the AI’s tendency to make up facts, which makes the output much more trustworthy.
- Real-Time, Up-to-Date Information: In an LLM, the knowledge usually tends to be limited to its last training date. With RAG pipelines, you simply update the external knowledge base, and the AI can tap into the very latest information without needing a retraining of the full model.
- Cost-Effective and Efficient: Retraining a large language model is extremely costly and time-consuming. Using RAG saves tremendous time and resources, as its ability to inject new or specialized domain knowledge can be done by simply updating the document database.
- Transparency and Verifiability: Because the AI is pulling from certain sources, RAG systems are sometimes able to show the user which documents or chunks of text were used in generating the answer as a means to check the facts.
Challenges of Building RAG Pipelines
While powerful, RAG pipelines are not without their shortcomings and bring their own set of challenges for developers to keep in mind:
- The “Junk In, Junk Out” Problem (Data Quality): The whole system is as good as the quality of documents in the knowledge base. This means that if the source documents have poor writing, biases, or incorrect information, then the RAG system will yield poor or incorrect answers.
- Chunking Dilemma: Choosing the right size for the document chunks is tricky. With chunks being too small, the AI could lose the bigger picture (context), whereas with larger ones, the search would be less specific, or the full chunk won’t fit into the LLM’s input.
- Increased Complexity and Speed: Complex processing steps are involved in RAG pipelines: query encoding, database search, retrieval, and generation. Time is added to the process. For real-time applications, the big challenge is managing this added delay, or latency.
- Retrieval Failure: The biggest point of failure is usually the search itself. If the step of retrieval itself fails to find the correct, most relevant documents, the LLM will not have the context it needs and will more than likely generate a poor answer, even if the correct information is in the database.
Final Words!
RAG Pipelines represent the game-changing solution to large language models’ biggest weakness: factual accuracy. Adding a really smart search function to RAG basically turned AI from a brilliant yet unreliable generalist into a well-researched expert, ready to face the most complex, domain-specific questions with confidence and verifiable facts. It is a multi-step procedure that quickly became the norm for any AI system that needs precision and up-to-date knowledge.
To learn more, visit HiTechNectar!
FAQs
Q1. What does RAG mean in LLM?
Answer: It means the model looks up extra info before answering.
Q2. What is the difference between RAG and the RAG pipeline?
Answer: RAG is the idea; a pipeline is the actual setup that does it.
Q3. Is ChatGPT a RAG?
Answer: No, ChatGPT isn’t RAG by default, but it can be used in one.
Recommended Reading: Retrieval-Augmented Generation (RAG) Security: Risks and Mitigation Strategies