


The field of computer vision has seen significant advancements with the rise of deep learning models. For years, convolutional neural networks (CNNs) dominated tasks like image classification, object detection, and segmentation. However, the introduction of vision transformers (ViTs) has emerged as unbeatable competitors, challenging traditional approaches. Let’s explore the differences between them.
What are CNNs?
The CNN Era: The Old Reliable
CNNs have been widely used in image recognition for years. Think of them as super-smart artists who look at an image piece by piece, first at the edges, then at the shapes, and finally at the whole object.
Why is CNN popular?
- Great at Local Features: They excel at detecting patterns like edges, textures, and small details.
- Efficient with Small Datasets: They don’t need tons of data to perform well.
- Proven Track Record: Powering everything from facial recognition to medical imaging.
Vision Transformers: The New Challenger
Transformers Take Over Vision
Transformers ruled natural language processing (NLP). Then researchers thought of using it for images too, and in this way, vision transforms (ViTs) were born.
How Does ViTs Work?
Instead of scanning images bit by bit (like CNNs), ViTs break the image into patches, treat them like words in a sentence, and analyze relationships between them.
Why is it Getting Popular?
Better at Global Context: They understand the whole image, not just plans.
Scalability: With enough data, they outperform CNNs in some tasks.
Flexibility: The same architecture works for both text and images.
Architectural Foundations: Vision Transformers vs. Convolutional Neural Networks
Convolutional Neural Networks (CNN)
CNNs process visual data through a hierarchical system of convolutional layers. These networks apply learned filters that slide across the input image, detecting features at increasing levels of abstraction. The architecture’s strength lies in its:
- Local Connectivity: Each neuron is connected solely to a limited area of the input.
- Parameter Sharing: The same weights are used across spatial locations.
- Spatial Pooling: Progressive downsampling builds translational invariance.
Modern CNN variants like ResNet and EfficientNet have addressed initial limitations through innovations such as residual connections and neural architecture search, achieving remarkable performance across diverse vision tasks.
Vision Transformers
Vision transformers make changes in the transformer architecture from NLP for application to visual data. The approach involves:
- Dividing the input image into fixed-size patches (typically 16*16 pixels).
- Linearly transform each patch into a lower-dimensional space.
- Adding positional embeddings to retain spatial information.
- Processing the sequence through standard transformer encoder layers.
This architecture provides a global receptive field from the first layer, theoretically allowing better modeling of long-range dependencies compared to CNN’s local operations.
Vision Transformers vs. Convolutional Neural Networks
When comparing Vision transformers vs. Convolutional Neural Networks (CNNs), it is essential to understand their distinct approaches to image processing. Vision Transformers leverage self-attention mechanisms to capture global relationships within an image, while CNNs rely on convolutional layers to detect local patterns. This difference allows vision transformers to improve in tasks requiring a broader context, whereas CNNs are highly efficient for localized feature extraction.
Comparison Between Vision Transformers vs. Convolutional Neural Networks
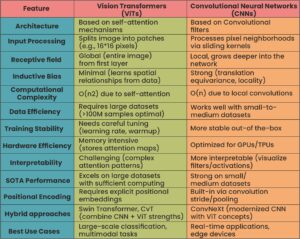
Key Technical Differences: Vision Transformers vs. Convolutional Neural Networks
Feature Extraction Mechanisms
CNNs excel at capturing local patterns through their convolutional filters. The hierarchical structure allows lower layers to detect simple features like edges and texture while deeper layers combine these into complex object representations. This design provides inherent advantages for:
- Spatial invariance to translation
- Efficient parameter utilization
- Robustness to input variations
Vision transformers simultaneously process all image patches using a self-attention mechanism. This enables:
- Direct modeling of the relationship between any two image regions
- Dynamic feature weighting based on global context
- Elimination of CNN-specific inductive biases
Real-World Applications of Vision Transformers & Convolutional Neural Networks
Where CNN Excel
- Medical imaging: Detecting tumors in X-rays and MRIs (e.g., Google’s DeepLesion model).
- Autonomous Vehicles: Real-time object detection utilizing models such as YOLOv4.
- Industrial Automation: Defect detection in manufacturing processes.
Where Vision Transformers Shine
- Large-Scale Image Recognition: Meta’s Deit (Data-efficient Image Transformer) for high-accuracy classification.
- Multimodal Learning: OpenAI’s CLIP combines ViTs with NLP for image-text understanding.
- Satellite Imagery Analysis: Mapping and environmental monitoring using global context.
Hybrid Approaches: Combining Vision Transformers & Convolutional Neural Network
Recent research explores hybrid models that integrate CNNs and ViTs to leverage their respective strengths:
- CoAtNet (Google research): Merges convolutional layers with self-attention for improved efficiency.
- ConViT (Facebook AI): Introduces gated positional self-attention to enhance ViTs with CNN-like properties.
Future Directions
Recent advancements show vision transformers outperforming CNNs in certain benchmarks, highlighting their potential in the evolving field of computer vision. However, CNNs still hold a significant edge in terms of computational efficiency and established applications. This difference allows vision transformers to excel in tasks requiring a broader context, whereas CNNs are highly efficient for localized feature extraction.
Research is actively exploring:
- Architectural hybridization (ConvNeXT, CoAtNet)
- More efficient attention mechanisms
- Scalable self-supervised learning approaches
- Unified architectures for multimodal tasks
The field appears to be converging toward models that combine the strengths of both paradigms while addressing their respective limitations.
Final Words: Are Vision Transformers Better Than CNNs?
The Vision Transformers vs. Convolutional Neural Networks debate reveals complementary strengths. CNNs remain superior for resource-constrained scenarios and small datasets, while ViTs show promise in data-rich environments requiring global context. The optimal choice depends on specific application requirements, with hybrid approaches likely dominating future developments. Practitioners should evaluate both architectures based on available training data, computational budget, deployment constraints, and accuracy requirements.
As the field evolves, the distinction between these paradigms may blur, giving rise to more versatile visual understanding systems that combine the best of both approaches.
To learn more, visit HiTechNectar!
FAQ
Q1: What is the difference between transformers and neural networks?
Answer: Transformers are a neural network type using self-attention for sequence data. Neural networks include broader architectures like CNNs/RNNs.
Q2: Are transformers more efficient than CNNs?
Answer: No, CNNs excel in image tasks with local processing. Transformers handle language dependencies but require more computation.
Recommended For You:
Proven Real-world Artificial Neural Network Applications!
The Impact of Artificial Neural Networks on Machine Learning